Ford's ITM Recall is a Troubling Sign for the Future of Software Defined Vehicles
- Tyler Betthauser
- Mar 10
- 18 min read

Updated: Mar 20
Motor 1 recently reported on a massive Ford Motor Company recall affecting over 4 million vehicles. The issue involves an Integrated Trailer Module (ITM) that can lose communication with the CAN bus, potentially disabling a trailer's brake lights and indicators. While recalls have become a weekly occurrence in the modern automotive landscape, one specific phrase in the recall report serves as a progenitor for a massive reckoning in the software-defined vehicle (SDV) movement: "allows for a potential race condition."
"allows for a potential race condition" to occur between the ITM and CAN Standby Control bit. A race condition occurs when multiple processes access shared data at the same time, with the results depending on execution order, and it’s this unpredictable timing that can cause the failure.
For a layperson, this sounds like just another glitch to be patched via an over-the-air (OTA) update. For a software engineer, it should set off every alarm bell in the building. A race condition occurs when multiple processes attempt to access shared data simultaneously, making the system's behavior dependent on unpredictable execution timing. In the context of a 4,000-pound truck hauling a heavy load, "unpredictable timing" is a polite way of saying the system is non-deterministic and fundamentally unsafe.
The inclusion of this specific defect reveals an insidious truth: the "SDV" label is being used to mask a lack of foundational engineering rigor which should already be inherent to the design of the mechatronics. In the traditional mechatronics domain, deterministic behavior is the baseline. Yet, as automakers rush to adopt the Agile methodologies of Silicon Valley, they are importing a "move fast and break things" culture into an environment where "breaking things" has lethal consequences. Aerospace engineers learned this decades ago through their own high profile scandals, yet the automotive industry seems determined to repeat those mistakes on a much larger scale.

This is not just a Ford phenomenon; it is an industry wide epidemic. According to U.S. vehicle recall trends, software-related failures are skyrocketing, yet luck is the only reason we haven't seen a total "Ignition Switch" style debacle play out in front of Congress. The industry is currently operating in a muddy middle, attempting to build complex, concurrent software systems using outdated procurement processes, in-sourcing and black box supplier modules they don't fully control.
To prevent a total collapse in consumer trust, Auto OEMs must move beyond being mere assemblers of parts and become world class architects of logic--which is not impossible given the mastery of hard parts.
Anatomy of the Race Condition
To understand how a trailer's brake lights can be extinguished by a software timing issue, we have to look at the architecture of embedded automotive systems. In modern vehicles, modules like the Integrated Trailer Module (ITM) and the Controller Area Network (CAN) gateway are not just simple switches; they are small, computers running complex firmware, often managed by a Real-Time Operating System (RTOS).
In the case of the Ford recall, the culprit is a race condition involving a Standby Control bit. In software engineering, a race condition occurs when the system’s behavior depends on the sequence or timing of (seemingly) uncontrollable events. When two or more threads of execution attempt to change shared data—in this case, the status of a single bit in a control register—the final result is determined by whichever thread wins the race to the CPU. If the wrong process changes the bit value to something unexpected, downstream processes can fail if there is not proper error handling in place (especially if the assumption is that the bit value can't be trusted in some instances). This is where an engineers typical procedural thinking can begin to fail if it is not sufficiently nuanced as a result of extensive experience or mentorship.
Hypothesizing the Failure: The ITM/CAN Handshake
Why would this happen in a production vehicle? We can hypothesize that the failure occurs during a power state transition, such as when the vehicle is waking up or entering standby mode. It is possible the failure looks something like this:

Imagine two distinct processes running in the vehicle’s software stack:
Process A (ITM Logic): Responsible for checking if a trailer is connected and signaling that the module needs to be "awake" to process brake signals.
Process B (CAN Power Management): Responsible for putting communication buses to "sleep" to save battery when it perceives the vehicle is inactive.
The Standby Control bit acts as a shared semaphore or flag between these two processes. In a properly architected system, these processes would use an atomic operation or a mutex (mutual exclusion lock) to ensure that only one process can touch that bit at a time. If Process A is in the middle of setting the bit to Active, but Process B interrupts it to set the bit to Standby because of a slight timing jitter in the system clock, the bit might end up in an inconsistent state.
The result? The ITM thinks it is communicating, but the CAN bus has already entered a standby state. The handshake is missed, the communication line goes dead, and the trailer brakes lose their signal.
The Problem with Black Box Concurrency
This type of bug is notoriously difficult to catch because it is non-deterministic. It might not happen during 9,999 startups, but on the 10,000th time—perhaps because of a specific temperature induced clock drift or a simultaneous interrupt from another system like the infotainment unit—the timing aligns perfectly to trigger the crash.
In a black box supplier model, the OEM may only see the output of the ITM. They don't see the internal threading model or how the supplier handled (or failed to handle) concurrency. Even internally developed software is often done in silos. If the supplier didn't use thread safe primitives—perhaps trying to save a few microseconds of execution time—the OEM has no way of knowing until the vehicles are in the hands of millions of customers.
Why Design Reviews Miss the Race
Traditional design reviews often focus on functional logic: "If X happens, then do Y." However, race conditions are a failure of temporal logic. A reviewer looking at the code for Process A might see that it correctly sets the bit. A reviewer looking at Process B sees it also behaves correctly. Without an integrated, system level view of how these processes interact in a high concurrency environment, the unpredictable timing remains a hidden landmine. Further confounding the development teams is a reliance on virtual environments and benches. These static, poor, representations of a moving vehicle are useful for creating proofs of concept but create a false sense of security if developers are only recreating incredibly simple use cases with very simple signals. Even the constant 12V power is unrealistic. By the time this brittle code makes it into a vehicle, running changes become incredibly expensive (and potentially more complex) to address. Add in a mix of multiple suppliers, OEM development teams, and limited test vehicles and it is easy to imagine why issues like this make it into customers hands.
The Ownership Mandate: Insourcing as a Survival Skill
The common industry refrain is that OEMs should focus on what they do best—building cars—and leave the software to the specialists. This logic is a trap. A trap that the traditional OEMs have attempted to ameliorate with tepid success. When a specialist supplier provides a compiled black box module, the OEM is less likely to perform the deep, line-by-line design reviews necessary to catch a race condition between the ITM and the CAN bus. Why staff an experienced engineer to oversee the supplier when that is the suppliers job? You cannot verify what you cannot see. If the supplier follows the requirements and passed the tests, then no problems. However, there is a trap door here as well. OEMs still need to be capable to understanding how to write and architect the requirements such that the software can be independently developed and integrated later.
To fix this, OEMs must own the entire software vertical. But insourcing for the sake of control isn't enough; the OEM must be better at software than the suppliers they are replacing. This means moving away from a model where software is a component bought at the lowest cost and moving toward a Software Factory model. In this environment, the OEM owns the kernel, the middleware, and the application layer, ensuring that every handshake between modules is documented, deterministic, and thread-safe.
However, this doesn't mean just hiring from Silicon Valley because "that's where the talent is." A car is not a phone or a piece of code running on a typical remote server. While abstractions like telematics can be borrowed from the tech world, we must resist making hiring decisions influenced by advocate shareholders. We need to grow a new version of the software engineer who specializes in the unique constraints of the automotive domain. A decade ago, this was the systems engineering push we saw where components were divided into systems which were owned by a class of systems engineers / architects that collaborated to ensure systems were properly integrated. We are seeing that role slowly be compressed into software engineering roles and the impact is that race conditions get missed or underappreciated.
Translating Tribal Knowledge into Syntax
The greatest untapped asset of a legacy OEM is not its assembly line, but its tribal knowledge of how vehicles are supposed to come together functionally—the century of hard-won intuition about how a vehicle behaves in the real world. The current crisis stems from a failure to translate this physical mastery into syntax. We are seeing a chasm between the people that can code and the people who understand the physics aren't writing the code, and the people writing the code don't understand the broader vehicle ecosystem, customers, and uses.
A world class automotive software practice requires engineers who can take the mechanical basics of vehicle dynamics and encode them into safety critical systems. If the person writing the code for the CAN Standby Control bit doesn't understand the physical behavior of a trailer brake under load, the code is doomed to fail. It becomes obvious why attempting to squeeze systems engineering into a purely software engineering role is going to become untenable. Auto OEMs are well known for having incredibly silo'd organizations. Vertical integration might just end up looking like groups of internally managed suppliers.
The Ultimate Appreciation of the Dynamic Environment of a Vehicle
Auto OEMs need to inculcate more skepticism from their engineers when architecting these systems and their requirements. For decades, vehicles were complex but fairly deterministic. If the assumption is that a system is inherently unstable, then designs can get complex but more robust. Error handling isn't free, but neither is warranty and labor costs.

Phase 1: The Initial Request and the Race Condition
The process begins with the vehicle’s Power Management Logic attempting to wake up the system. It sends a command to the CAN Register to set the Standby_Bit to 0, which is the signal for the system to Wake.
However, at this exact moment, a physical stressor—such as a voltage dip during engine cranking or high electrical resistance—introduces a timing jitter. When the ITM Defensive Logic attempts to read that same register, the race condition occurs: the hardware returns a 1 (Standby) instead of the intended 0.
Phase 2: Multimodal Validation
Instead of blindly obeying the bit, the defensive ITM enters a Multimodal Validation phase. It ignores the register for a moment and polls the Vehicle Data Bus for physical evidence of the truck's actual state. A static wait timer is not appropriate. It asks three critical questions:
Is the vehicle moving? (The Bus reports 65 MPH).
Is the driver pressing the brakes? (The Bus reports the pedal is PRESSED).
Is the vehicle in a special towing mode? (The Bus reports Tow-Haul is ACTIVE).
The ITM logic identifies a conflict: the software bit says commands the shutdown processes, but the physical reality of the truck says to perform functions as normal.
Phase 3: Resolution
Because the system is designed to be skeptical of its own internal state, it triggers a remediation. The ITM issues a re-sync command back to the CAN Register, essentially demanding a status refresh to clear any transient errors or dirty reads.
The Register responds with the correct, updated state (0 for Wake)--assuming there are no other extenuating circumstances keeping the state of the bus in doubt. Having successfully reconciled the logical signal with the physical environment, the Validation is marked as a success. The ITM then resumes its primary safety function: monitoring the bus for brake inputs and ensuring the trailer's lights are engaged, even though the initial handshake had failed.
This demonstrates that "Back to Basics" engineering isn't about avoiding complexity; it's about using known adverse conditions seen in a vehicle (knowing a moving truck shouldn't have a sleeping trailer module) to build a system that is resilient to the unpredictable nature of hardware. Obviously, being a third-party to the OEM means we do not have all the information, but the thought exercise is still a useful demonstration of what we should be expecting from these engineering teams. Launching a super car is fantastic! Integrating next generation technology is a compelling advancement, but there is something to be said about doing basics exceedingly well first.
What Should Have Caught This: The Engineering Gap
A race condition making it to 4 million customers is a failure of the safety net. To close this gap, the industry must re-embrace the fundamentals:
Integrated FMEA
Merging Software and Mechatronics Failure Mode and Effects Analysis to identify how logical errors manifest as physical hazards.
Way too often, software engineers in automotive are completely averse to using useful tools and frameworks to built better systems which have been used in the mechanical/mechatronic realm for decades. With all that code running at the same time, it is effectively non-deterministic, they say! This is unbelievably lazy and unimaginative thinking which prevents developers, engineers, and architects from designing fault tolerant systems. Yes, it would be much simpler if everything worked according to the requirements, suppliers made nearly perfect parts, or customers used the systems in ways we always intend--but that world doesn't exist. As we discussed heavily in When the Dashboard Goes Dark: The Car Conservatory’s Guide to Digital Failure , software and hardware have impacts on each other not only from a performance perspective (How many operations can this hardware enable me to perform every milisecond?) but also from a reliability standpoint as well (how many writes can I get away with before the memory wears out?). The intersection of these discussions result in an opportunity to create a failure modes effects analysis that can identify design choices early which will have impacts that need to be mitigated earlier.
In the case with Ford here, a component diagram, a few sequence diagrams, and a few line items on an FMEA would have gone a long way to preventing a race condition such as this one. Fault-tree analysis, 5-Whys, and ishikawa diagrams can be particularly good, structured, brainstorming tools that can help teams to identify edge cases that otherwise might be non-obvious or statistically low risk failures but have outsize impact on the customer experience.
Here are a few examples of the hypothetical we discussed above:

Visualizing the System Identifies the Points of Failures
A component and connector diagram provides the map of the system's logical geography. In the context of our FTA and 5-Why analysis, this diagram allows us to see the interfaces—the exact points where data handshakes occur and where the race condition is physically and logically possible.
By visualizing the ITM as a participant in a larger network rather than an isolated part, we can pinpoint how systems relate with each other and it becomes apparent where multiple systems or components might be accessing the same data. This example is a little simple, though.
This diagram assumes a centralized gateway architecture where the Power Management and Vehicle Gateway (Speed/Brake) signals are broadcast across the bus, while the ITM resides on a specific sub-network or control branch.
The Shared Memory Bottleneck (FTA Link): The line between the Power Management Service and the ITM Communication Handler is the Hardware Register. In our FTA (below), this is the root of the race condition branch. The diagram shows that both components are fighting over this specific piece of real estate. Without a mutex or atomic operation, the timing jitter identified in the FTA manifests right here.
The Proxy Bypass (5-Why Link): The 5-Why analysis (also below) identified that a lack of proxy data was the reason the bug reached production. The diagram shows a separate connector from the Vehicle Gateway to the ITM Communication Handler. In the failed design, this connector was likely inactive or ignored. The remediation is simply activating this data path so the Defensive Logic Engine has the Speed and Brake signals to challenge the Standby Bit.

Explaining the Fault Tree Logic
The analysis begins with the Top Event, which is the total failure of the trailer brake and indicator signals. For this failure to occur, the system must follow one of two main paths. Either the ITM has remained in Standby mode when it should be active, or the CAN Bus signal itself has been interrupted by physical stressors.
The path toward the ITM incorrectly remaining in standby is driven by an AND Gate, meaning two distinct failures had to happen simultaneously. First, a race condition must occur, likely triggered by a timing jitter during a power transition or unsafe access to shared data. Second, there must be a lack of defensive proxy validation. If the software had been designed to cross-reference the Standby command with the vehicle's actual speed or Tow Haul Mode status, the race condition would have been neutralized before it reached the top event.
On the hardware side, the physical stressors act through an OR Gate, meaning any one of these factors could be the catalyst that disrupts the timing. A significant Voltage Drop during an engine crank can cause the ITM to reset or lag behind the central power management logic. Similarly, high resistance or vibration at the trailer connector can create signal flicker, causing the software to misinterpret a single bit and enter a safe/standby state to protect the bus.
By visualizing the failure this way, it becomes clear that while the race condition is the software trigger, the lack of proxy validation is the structural engineering gap that allowed the physical stressors to manifest as a safety recall for 4 million vehicles.
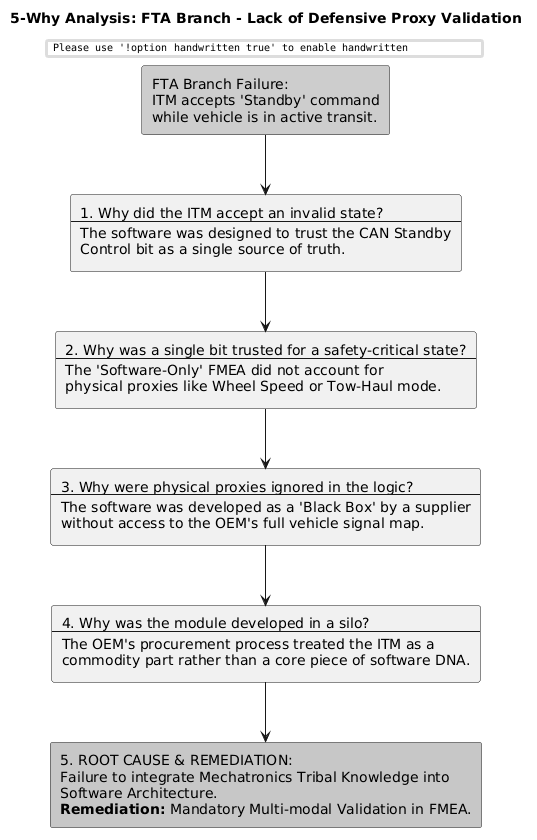
Using the 5-Why to Systematically Reason through the FTA Branches
In this model, the Fault Tree Analysis (FTA) acts as the Pre-Mortem. By mapping out how a trailer light failure could happen, you naturally arrive at the potential race condition branch. This discovery triggers a 5-Why investigation during the design phase—not to find out why it failed in the field, but to find out why the architecture allows it to fail at all. The output of that 5-Why then becomes a high priority line item in the FMEA, with a specific risk remediation (like the defensive code) that lowers the RPN before the first prototype is even built.
The Sample Size Fallacy
Part of the FMEA is to define a Risk Priority Number (RPN). An RPN is supposed to dictate the known constraints, how often they happen, and how detectable they might be, of the system and how they are ameliorated in the design. in early testing means nothing if the sample size is statistically insignificant compared to a multi-million unit build volume. The RPN is a numerical score (1–1000) used in Failure Modes and Effects Analysis (FMEA) to rank the risk of potential failures by multiplying Severity (S), Occurrence (O), and Detection (D) ratings (typically 1–10). It identifies, prioritizes, and helps mitigate critical risks. RPN is a notoriously fudgeable number. And, by the time FMEAs are being done for components and software, a huge chunk of cash has been sunk--which already compromises the incentive structures to make decisions in favor of the customer. A key issue with these early FMEAs and engineering fleets is their numbers. Some of the early fleets might not even be capable of detecting these race conditions. and even if they do, might appear to be so rare that leaders are reticent to make the appropriate changes (no matter the safety impact).
We'll build a toy model to demonstrate the impact of an FMEA activity and modeling the failure rate of the trailering system based on the small engineering fleets that tend to be used for testing software and hardware. These are obviously not true for this particular case, but meant to be more representative of how you might use a multivariate stochastic model with the FMEA to make better decisions about whether to roll the dice or make a change.
The Variables: Defining the Physics of Failure
The simulation uses a Hierarchical Monte Carlo method to bridge the gap between a 50-vehicle development fleet and a 4,000,000-unit retail deployment. It is built on three primary pillars of stress (these are not the only ones and not necessarily representative of the Ford specific issue, but they demonstrate a point). These would be line items on the FMEA (that should be) conducted between the software and mechatronics development teams:
OS Jitter: We chose a lognormal distribution for OS timing jitter (μ=25ms,σ=0.2). This represents the unpredictability of real time processing. A race condition is essentially a timing failure; it occurs when a high priority task is delayed long enough to collide with a hardware state change.
System Voltage: Modeled as a normal distribution (μ=12.4V,σ=0.4). Voltage is the primary physical stressor. In modern automotive modules, low voltage increases signal propagation delay and reduces noise margins, making the system more vulnerable to logic errors.
Correlation: A critical assumption in this model is that logic and physics are not independent. If system voltage drops below 11.5V, OS jitter increases by 40%. This simulates a power constrained microcontroller struggling to maintain stable clock speeds or handling increased interrupt overhead from power management routines.
Cluster Sampling: Unlike simple reliability models, we introduced a batch impact factor. This accounts for the reality that automotive components are produced in production windows. If a specific batch of chips has marginal silicon or a specific software build has a slight compiler drift, the failures will cluster.
The Sigma Stress Boundaries
The inputs were passed through Sigmoid Stress Boundaries inspired by ISO 16750-2. We chose sigmoids because reliability failures rarely follow a linear Pass/Fail logic; instead, they exist as a probability that increases exponentially as stressors reach a threshold.
Voltage (10.2V): The system is designed to be robust at the 12.4V mean. The sigmoid threshold was set at 10.2V to represent the end stress—extreme events like cold cranking or heavy accessory load where the hardware is pushed to its limit.
Jitter Cliff (62ms): Many OS cycles complete in 25ms. By setting the failure threshold at 62ms, we ensure the race condition is truly rare. It only occurs when a massive jitter spike coincides with a significant voltage dip.
Analysis of Results: The "Hidden" Failure
The recent simulation results provide a perfect case study for the statistical blind spot:
Metric | Result | Meaning |
Latent Failure Rate (p) | 0.000101 | The bug affects roughly 101 vehicles per million. |
Detection Probability | 91.96% | There is a 92% chance the test fleet sees the bug. |
Confidence Check | FAIL | Statistical blindness exceeds the 95% safety threshold. |
Field Events | 403 Units | Despite a mostly clean test, 400+ cars will fail in public. |
The Probability of Detection vs. The 95% Goal: Even though a 92% detection rate seems high, reliability engineering standards (and many safety protocols) require a 95% confidence level. Because the engineering fleet only runs 25,000 cycles, the model calculates that there is an 8% chance you could run the entire test and see zero failures, simply because the bug is so rare (101 ppm). This 8% chance of missing the bug is a Fail in high reliability environments.
The Retail Explosion: The 403 field events are a direct consequence of the p value meeting the massive retail volume. In engineering, 101 ppm is a tail risk that is hard to find; in retail, 101 ppm is a decently sized quality issue that triggers a technical service bulletin or a recall.
The Gap: The model identified that to move from 91.96% to the required 95% confidence, the fleet must grow to 60 vehicles. This is the core value of the model: it translates an abstract feeling of risk into a specific, defensible engineering requirement (add 10 cars or increase cycles).
As OEMs become more reliant on smaller engineering fleets and virtualization, it will become mathematically not possible to detect these integration issues and fix them unless massive strides are made in telemetry, instrumentation, and world model building. Recalls and technical service bulletins will continue to rise over the next decade or so. And, reliability models are only as good as the estimations of occurrence and detection. Deeming an issue as rare, that actually isn't, will make its way into the field at huge numbers.
Telemetry and Figures of Merit
Properly executed FMEAs should have highlighted specific telemetry data points that would have alerted quality teams and technicians to these failures in the field much sooner. A proverbial living FMEA. The assumptions and predictions can then be measured against the results customers are not necessarily reporting in warranty claims but as they happen in the vehicles. In our hypothetical (and in the real world) the ITM should have reported as a DTC an incongruity noted between the standy bit--indicating a failure in the trailer brake lamps. These data points would have made it very easy to understand the nature of why these race conditions are occurring so they could be more expeditiously fixed via an Over-the-Air Update (OTA) or Dealer Flash.
A living FMEA then also becomes more front and center throughout the development process.
A Virtualization Trap
World models have come quite a long way in the last decade. However, most virtualized development is limited to running scripts with simple functions like a single button press or a periodic cycling of a can signal. There are exceptions in the ADAS realm where there is more data from cameras, temperature sensors, LIDAR/RADAR, GPS, and audio to replay scenarios with development code. Basic functionality can be somewhat reliably developed and tested. However, hardware is not so easy to instrument and model virtually. In the case of increased resistance on a pin or voltage drop, or the race conditions we have talked about in the article. Failure rates on benches should not make anyone feel confident about the future. These contraptions are incredibly useful for basic hardware stress testing and ensuring core functionality does not brick an engineering vehicle; however, there are no replacements for a vehicle or a customer.
Cheaper development will continue to result in issues appearing long after the product has already been in customers hands.
Implications for the Aftermarket
So, what are the implications of these types of issues for the independent shops and out of warranty vehicles? Firstly, shops need to be capable of becoming skilled with networks and diagnosing them. Investing in tools that can reliably get access to signals on the CAN Bus is essential. Secondly, having the knowledge and wherewithal to recognize when it is time to replace a part and when it isn't. OEMs have a responsibility to make this clear for technicians and customers, but historically they have not been able to do so. Shops are businesses and they are meant to make money. However, The Car Conservatory also believes that we also should be good stewards of value for customers.



Comments